>> Jump to the results
Introduction
Since PyXLL was first released almost 5 years ago there have been a few other addins attempting to extend the benefits of Python to Excel programming. Seeing the latest attempt, ExcelPython, got me thinking about what approaches these other packages were taking and whether there were any real differences between what they offer and what is already possible with PyXLL. ExcelPython is now part of xlwings.
PyXLL was written from the ground up to be the best possible way of integrating Python code into Excel. It was born out of years of working alongside Excel users who understand Excel very well but work in an environment where VBA doesn’t cut it. I saw spreadsheets mailed around only later for bugs to be found with no way of tracking where those sheets were in use; reams of VBA that could be massively simplified with a few lines of well written Python; code copied and pasted all over different spreadsheets; nothing checked in to any kind of version control system – the potential advantages of a tool like PyXLL were all too obvious.
Since then it has evolved to meet the demands of the worlds largest banks, hedge funds and engineering firms.
Excel Functions (UDFs)
The bread and butter of any Excel workbook is formulas. It’s what Excel does best, and so for this comparison what I was interested in looking at was how the different offerings perform at that most fundamental task.
To my surprise most of the Python/Excel tools are particularly poor in this most basic of areas. Instead, they provide a Python command prompt in Excel and an object API for interacting with Excel. Anyone who has used win32com is probably already familiar with calling into Excel from a Python prompt or IPython notebook, so that doesn’t seem to add much value (especially when you consider the Excel API is already well understood and documented).
[table]
Product,UDFs,Comments
PyXLL, Yes, “Advanced features like multi-threading, asynchronous functions and ‘macro equivalent functions'”
ExcelPython, Limited, “Basic functions only, all calls are made through VBA macros in a workbook”
DataNitro, Limited, “Basic functions only, and only works in first launched Excel”
xlwings, Limited, Wrapper around ExcelPython
[/table]
For this test I decided to focus on PyXLL and ExcelPython (part of xlwings).
Setting up the test
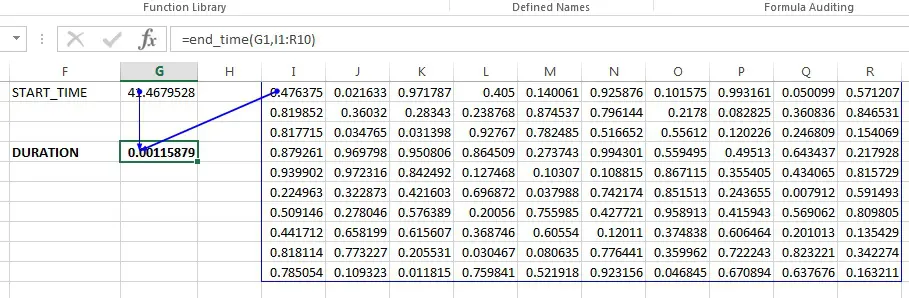
Most Excel spreadsheets have a number of simple formulas taking a few values and returning a single value, and formulas taking and returning large ranges of data. There are plenty of tools to speed up Python code (numpy, Cython, Numba etc) so I wanted to find out what the overhead of calling a Python function from Excel is. To do that I created a simple python function to return time.clock() (start_time), another function that would take that time as an argument and return a random number (test_func), and a final function that would take a range of cells and the start time and return the elapsed time (end_time).
By setting up a sheet with lots of cells all calling test_func all dependent on start_time, and a single cell calling end_time dependent on all of the test_func cells and the start_time then timing how long it takes to calculate all those cells should be just as simple as pressing Shift+F9 to recalculate the sheet.
from pyxll import xl_func
import numpy as np
import time
@xl_func(': float', volatile=True)
def start_time():
return time.clock()
@xl_func('var x: float')
def test_func(x):
return np.random.random()
@xl_func('float start_time, var x')
def end_time(start_time, x):
return time.clock() - start_time
Setting up the dependencies in this way means that all the cells evaluating test_func will have been called after start_time and before end_time. The test_func function is deliberately simple as we’re not so interested in the performance of the actual function for this test, as long as it’s the same in both test cases.
This worked great with PyXLL, so I went to do the same thing with ExcelPython. I came up against the first problem then – I couldn’t find how to make an ExcelPython function volatile! A volatile function is one that Excel will always recompute, even if it’s inputs haven’t changed. It’s very useful, and I’d used it for the start_time function so that recalculating the sheet would always cause start_time (and therefore also the cells that depend on it) to be called.
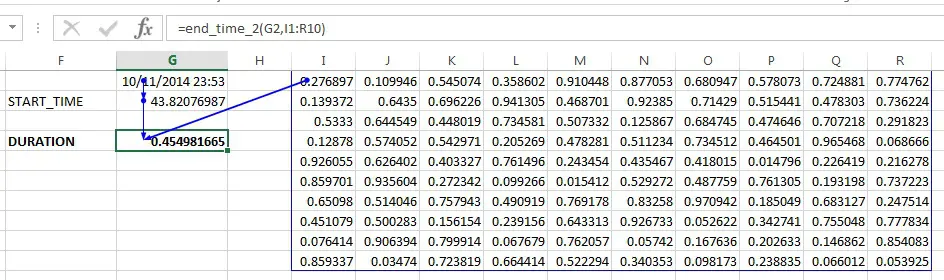
Instead, I had to use a slightly hacky trick of passing in the current time to the start_time function.
from xlpython import *
import numpy as np
import time
# pass in =NOW() as function cannot be made volatile
@xlfunc
def start_time_2(x):
return time.clock()
@xlfunc
def test_func_2(x):
return np.random.random()
@xlfunc
def end_time_2(start_time, x):
return time.clock() - start_time
Results
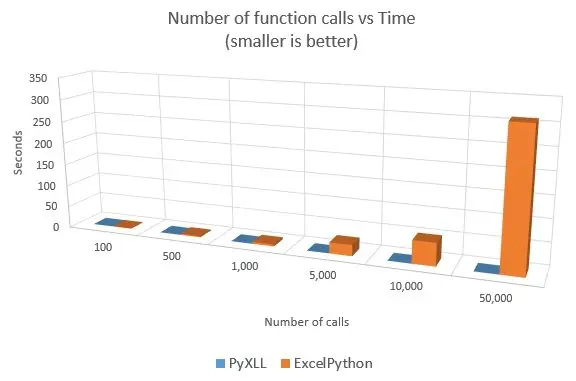
The results were quite surprising. I’d expected that ExcelPython might be a bit slower as it has to go through VBA to a COM server running in a separate process. PyXLL is all in-process and uses the Excel C API directly without using any VBA or COM. it turns out in this test ExcelPython was a lot slower than PyXLL, as the following results show (all times in seconds).
[table]
Cells,PyXLL,ExcelPython,Times Faster
100,0.001641,0.481163,293.18
500,0.007748,2.427637,313.31
1000,0.015495,4.793235,309.35
5000,0.050574,25.094259,496.19
10000,0.085134,51.347536,603.14
50000,0.291185,311.025084,1068.13
100000,0.544709,,
[/table]
Doing lots of function calls like this is one way that Excel users may structure their spreadsheets. Because doing so many small functions has such an overhead in ExcelPython I was interested to see what would happen if instead of calling lots of functions I just called a single function with a table of static data.
For this test I used the same code but substituted the block of function calls with a block of static data.
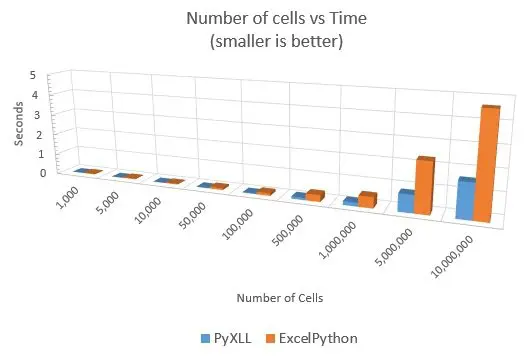
This showed that it really was the individual function calls that ExcelPython was struggling with. Passing large ranges of data worked better, but PyXLL was still the clear winner.
[table]
Cellls,PyXLL,ExcelPython,Times Faster
1000,0.000108,0.026491,244.19
5000,0.001235,0.036692,29.70
10000,0.002710,0.037621,13.88
50000,0.024280,0.088298,3.64
100000,0.029384,0.121576,4.14
500000,0.103459,0.314327,3.04
1000000,0.170047,0.507612,2.99
5000000,0.811739,2.328209,2.87
10000000,1.615331,4.643208,2.87
[/table]
Conclusion
PyXLL is well established and was designed for performance so that as much of the time spent calling your functions is actually spent in your functions as possible. There is always going to be some time spent constructing the Python values, but by minimizing that it means your spreadsheets can be as responsive as possible.
ExcelPython in comparison is much newer and so perhaps it’s not surprising that it has some catching up to do. The different approach ExcelPython has taken by using a combination of COM and VBA rather than targeting the Excel C API directly, I expect, is part of the cause of the significant performance differences.
PyXLL goes further with features to help you make responsive worksheets. It makes it easy to write asynchronous functions that allow Excel to continue running while computation is done in the background (in another thread, process, or just waiting for IO). You can also mark your functions as thread_safe and Excel will call your functions from multiple threads from a thread pool. For Python functions that don’t block the GIL (eg ones written with c extensions or IO bound functions like database access) this can be a big help.
As important as performance is the differences in features between PyXLL and ExcelPython. That’s another blog post in itself, but a couple of things stood out to me while doing this test. I found it annoying that with ExcelPython the functions only existed in one workbook. When I wanted to test something out in another workbook I had to set it up and save it as an xlsm file and copy some code. With PyXLL the code used is configured just once. I also found that calling a function with a date with ExcelPython just gave me a number, but PyXLL’s type system makes it easy to specify what types are expected and it handles the conversion automatically. Perhaps defaulting to the ‘var’ type for all arguments if no signature is supplied would be a good feature for a future version of PyXLL, but having the ability to specify the types (and register custom types) is pretty useful.
The spreadsheet and code used for these tests is here: perftest.zip.