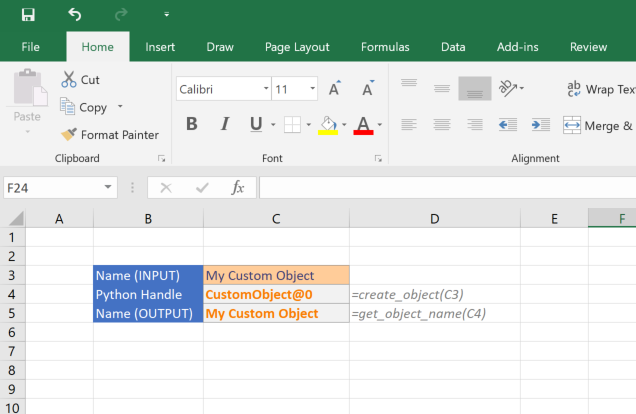
PyXLL can pass Python objects between Excel functions even if the Python object can’t be converted to a type that can be represented in Excel. It does this by maintaining an object cache and returning handles to objects in the cache. The cached object is automatically retrieved when an object handle is passed to another PyXLL function.
Even for types that can be represented in Excel it is not always desirable to do so (for example, and Pandas DataFrame with millions of rows could be returned to Excel as a range of data but it would not be very useful and would make Excel slow).
Instead of trying to convert the object to an Excel friendly representation, PyXLL can cache the Python object and return a handle to that cached object to Excel. The actual object is held in PyXLL’s object cache until it is no longer needed. This allows for Python objects to be passed between Excel functions easily, and without the complexity or possible performance problems of converting them between the Python and Excel representations.
Note
Objects returned from Excel to Python as cached objects are not copied. When an object handle is passed to another function, the object retrieved from the cache is the same object that was previously returned.
You should be careful not to modify these objects. Instead, if you need to modify the object, you should copy or clone the object and only modify the copy.
The following example shows one function that returns a Python object, and another that takes that Python object as an argument:
from pyxll import xl_func
class CustomObject:
def __init__(self, name):
self.name = name
@xl_func("string name: object")
def create_object(x):
return CustomObject(x)
@xl_func("object x: string")
def get_object_name(x):
assert isinstance(x, CustomObject)
return x.name
Note that the object is not copied. This means if you modify the object passed to your function then you will be modifying the object in the cache.
When an object is returned in this way it is added to an internal object cache. This cache is managed by PyXLL so that objects are evicted from the cache when they are no longer needed.
When using the var type, if an object of a type that has no converter is returned then the object
type is used. When passing an object handle to a function where the argument type is the var type
(or unspecified) then the object will be retrieved from the cache and passed to the function automatically.
When writing an Excel macro, if you need to access a cached object from a cell or set a cell value
and cache an object you can use the XLCell class. Using the XLCell.options
method you can set the type to object before getting or setting the cell value. For example:
from pyxll import xl_macro, xl_app, XLCell
@xl_macro
def get_cached_object():
"""Get an object from the cache and print it to the log"""
# Get the Excel.Application object
xl = xl_app()
# Get the current selection Range object
selection = xl.Selection
# Get the cached object stored at the selection
cell = XLCell.from_range(selection)
obj = cell.options(type="object").value
# 'value' is the actual Python object, not the handle
print(obj)
@xl_macro
def set_cached_object():
"""Cache a Python object by setting it on a cell"""
# Get the Excel.Application object
xl = xl_app()
# Get the current selection Range object
selection = xl.Selection
# Create our Python object
obj = object()
# Cache the object in the selected cell
cell = XLCell.from_range(selection)
cell.options(type="object").value = obj
Instead of using a cell reference it is also possible to fetch an object from the cache by its handle.
To do this use get_type_converter to convert the str handle to an object, e.g.:
from pyxll import xl_func, get_type_converter
@xl_macro("str handle: bool")
def check_object_handle(handle):
# Get the function to lookup and object from its handle
get_cached_object = get_type_converter("str", "object")
# Get the cached object from the handle
obj = get_cached_object(handle)
# Check the returned object is of the expected type
return isinstance(obj, MyClass)
When Excel first starts the cache is empty and so functions returning objects must be run to populate the cache.
PyXLL has a feature that enables functions to be called automatically when loading a workbook (Recalculating On Open). When a workbook is opened any cell containing a function that has been set to recalculate on open will be recalculated when that workbook is opened and calculated.
By default, all functions that return the type object are marked as needing to be recalculated
when a saved workbook is opened. This ensures that the cache is populated at the time the workbook
opens and is first calculated and avoids the need to fully recalculate the entire workbook.
For functions that take some time to run, or any other functions that should not be recalculated
as soon as the workbook opens, use recalc_on_open=False in the xl_func decorator, eg:
from pyxll import xl_func
@xl_func(": object", recalc_on_open=False)
def dont_calc_on_open():
# long running task
return obj
You can change the default behaviour so that recalc_on_open is False for object functions unless
explicitly marked otherwise by setting recalc_cached_objects_on_open = 0, e.g.
[PYXLL]
recalc_cached_objects_on_open = 0
Note
This feature is new in PyXLL 4.5. For prior versions, or for workbooks saved using prior versions, the workbook will need to be recalculated by pressing Ctrl+Alt+F9 to populate the cache.
Rather than having to recalculate functions to recreate the cached objects PyXLL can serialize and save cached objects as part of the Excel Workbook Metadata.
This is useful if you have objects that take a long time to calculate and they don’t need to be recreated each time the workbook is open.
Caution should be used when deciding whether or not to use this function. It is usually better to source data from an external data source and load it in each time. Referencing an external data source ensures that you always see a consistent, up to date view of the data. There are times when saving objects in the Workbook is more convenient and we only advise that you consider which option is right for your use-case.
Saving objects as part of the workbook will inevitably increase the size of the workbook file, and so you should also consider how large the objects to be saved are. Excel should never be used as a replacement for a database!
To have PyXLL save the result of a function use the save parameter to the object return type:
from pyxll import xl_func
@xl_func(": object<save=True>")
def function_with_saved_result():
# Construct an object and return it
return obj
When calling a function like the one above the object handle will be slightly different to a normal object handle. For objects that are saved the object handle needs to be globally unique and not just unique in the current Excel session. This is because when the object is loaded it will keep the same id and that must not conflict with any other objects that may already exist in the Excel session. If you are using your own custom object handle you must take this into consideration.
Objects that are to be saved must be pickle-able. This means that they must be able to be serialized
and deserialized using Python’s pickle module. They are serialized and added to the workbook metadata
when the workbook is saved.
See https://docs.python.org/3/library/pickle.html for details about Python’s pickle module.
Note that the Python code required to reconstruct the pickled objects must be available when opening a workbook containing saved objects in order for those objects to be deserialized and entered into the object cache.
Loading saved objects can be disabled by setting disable_loading_objects = 1 in the
PYXLL section of the pyxll.cfg config file.
[PYXLL]
disable_loading_objects = 1
Note
This feature is new in PyXLL 5.0.
The method of generating object handles can be customized by setting get_cached_object_id in the PYXLL
section of the config file.
The generated object handles must be unique as each object is stored in the cache keyed by its object handle. For objects that will be saved as part of the workbook it’s important to use a globally unique identifier as those objects will be loaded with the same id later and must not conflict with other objects that may have already been loaded into the object cache.
Only one function can be registered for generating object handles for all cached objects. Different formats of object handles for different object types can be generated by inspecting the type of the object being cached.
The following example shows a simple function that returns an object handle from an object. Note that
it uses the ‘id’ function to ensure that no two objects can have the same handle. When the kwarg save
is set to True that indicates that the object may be serialized and saved as part of the workbook
and so a globally unique identifier is used in that case.
def get_custom_object_id(obj, save=False):
if save:
return str(uuid.uuid4())
return "[Cached %s <0x%x>]" % (type(obj), id(obj))
To use the above function to generate the object handles for PyXLL’s object cache it needs to be configured
in the pyxll.cfg config file. This is done using the fully qualified function name, including the
module the function is declared in.
[PYXLL]
get_cached_object_id = module_name.get_custom_object_id
The save kwarg in the custom object id function indicates whether or not the object may be saved in
the workbook. When objects are saved the same id is reused when loading the workbook later, and so these
ids should be globally unique to avoid conflicts with other existing objects. See Saving Objects in the Workbook.
Note
Prior to PyXLL 5.0 the custom object handle function did not take the save kwarg.
If you have a function that you want to return an object in some cases and a primitive value,
like a number or string, in other cases then you can use the skip_primitives parameter
to the object return type.
from pyxll import xl_func
from random import random
@xl_func("int x: object<skip_primitives=True>")
def func(x):
if x == 0:
# returned as a number to Excel
return 0
# return a list of values as an 'object'
array = [random() for i in range(x)]
return array
When skip_parameters is set to True then the following types will not be returned as object handles:
int
float
str
bool
Exception
datetime.date
datetime.datetime
datetime.time
If you need more control over what types are considered primitive you can pass a tuple of types as the
skip_primitives parameter.
Whenever PyXLL is reloaded the object cache is cleared. This is because the cached objects may be instances of old class definitions that have since been reloaded. Using instances of old class definitions may lead to unexpected behaviour.
If you know that you are not reloading any classes used by cached objects, or if you are
comfortable knowing that the cached objects may be instances of old classes, then you can
disable PyXLL from clearing the cache when reloading. To do this, set clear_object_cache_on_reload = 0
in your pyxll.cfg file.
This is only recommended if you completely understand the above and are aware of the implications
of potentially using instances of old classes that have since been reloaded. One common problem
is that methods that have been changed are not updated for these instances, and isinstance
will fail if checked using the new reloaded class.
[PYXLL]
clear_object_cache_on_reload = 0
To have your functions recalculated automatically after reloading, and repopulate
the object cache, you can do so using the recalc_on_reload option to xl_func
as desribed in the section Recalculating On Reload.